|
I am a Ph.D. student at The University of Texas at Austin in the Department of ECE, advised by the wonderful Prof. Joydeep Ghosh (previously by Prof. Edison Thomaz). I've also been affiliated with IDEAL, WNCG, IFML, and iMAGiNE. My research focuses on resource-efficient and data-centric machine learning, multimodal sensing, and human-centered AI. Previously, I interned at Bell Labs, Cambridge, UK (Device Intelligence team, led by Dr. Fahim Kawsar), advancing foundation models for health sensing. Before my Ph.D., I was a Data Scientist at Ericsson R&D, researching AI/ML solutions for next-generation telecom systems, and at SmartCardia – an EPFL spin-off in AI-driven wearable healthcare. In a past life, I was a Research Assistant at Solarillion Foundation, exploring on-device ML. I earned my Bachelor's from SSN College of Engineering, where I also conducted early research in ML, IoT, and HCI. Outside research, I enjoy traveling, exploring Indian classical and world music, badminton, and DotA. |
where resource := data, sample, label, model, parameter, compute, etc. Here are a few keywords that might best describe my research interests (present/past, hopefully in the future!). |
|

|
|
 |
|
 |
|
 |
pdf /
abstract /
bibtex
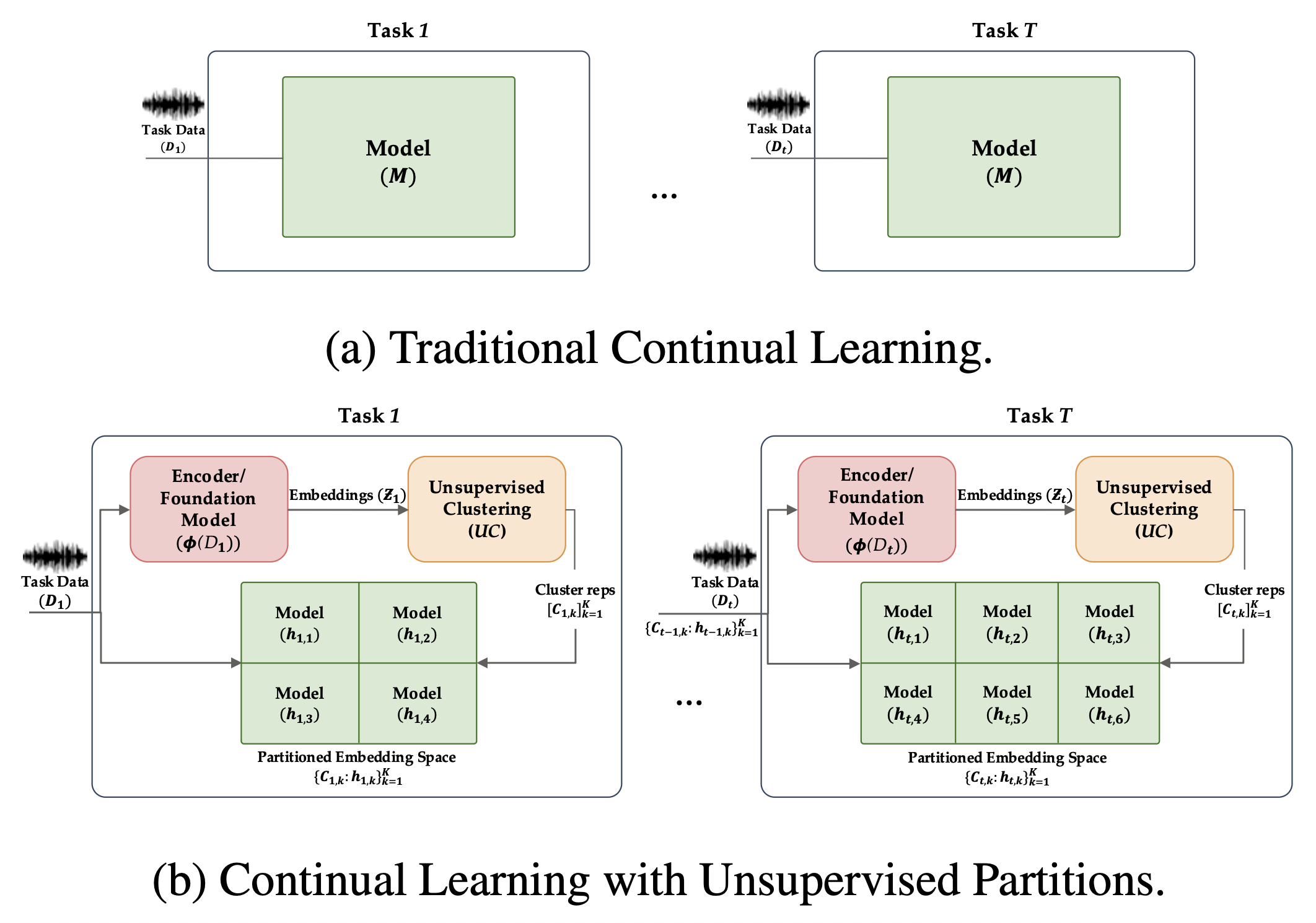
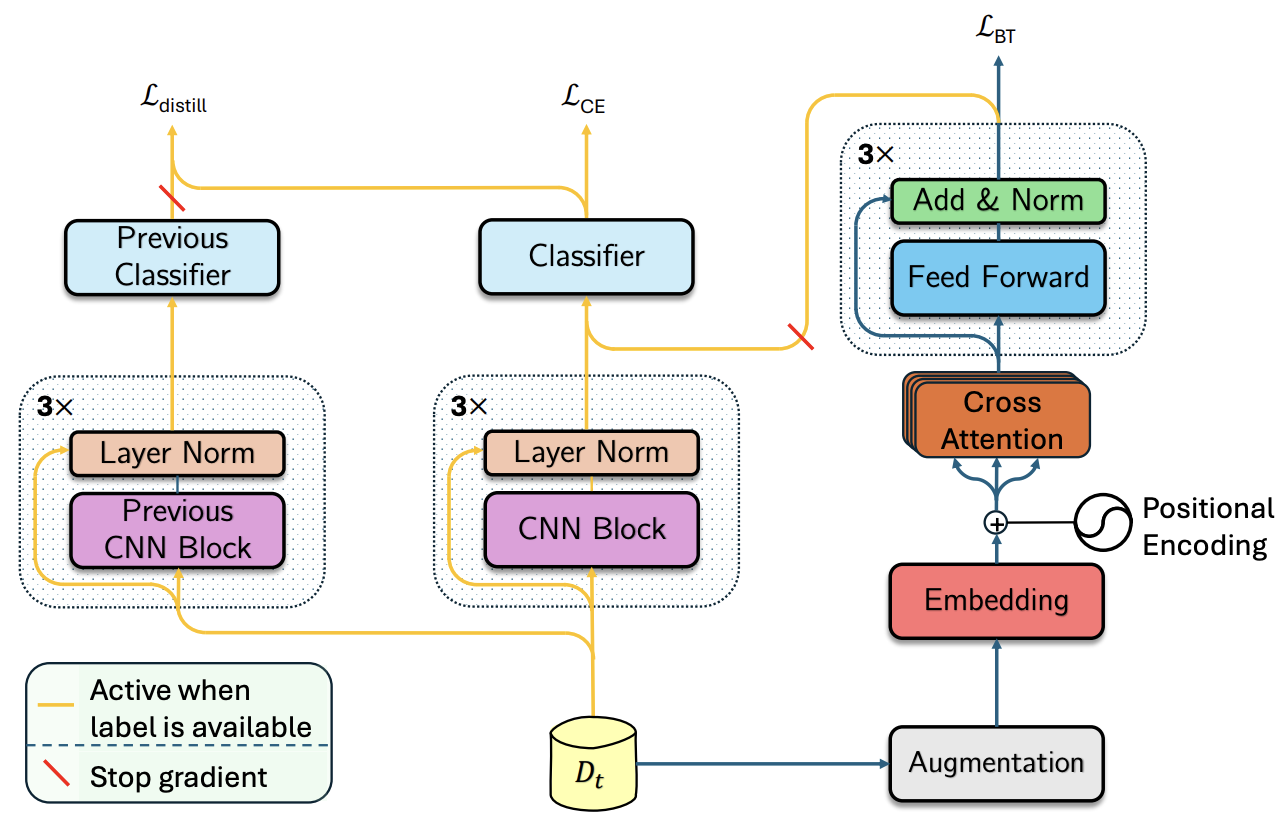
The rise of deep learning has greatly advanced human behavior monitoring using wearable sensors, particularly human activity recognition (HAR). While deep models have been widely studied, most assume stationary data distributions - an assumption often violated in real-world scenarios. For example, sensor data from one subject may differ significantly from another, leading to distribution shifts. In continual learning, this shift is framed as a sequence of tasks, each corresponding to a new subject. Such settings suffer from catastrophic forgetting, where prior knowledge deteriorates as new tasks are learned. This challenge is compounded by the scarcity and inconsistency of labeled data in human studies. To address these issues, we propose CLAD-Net (Continual Learning with Attention and Distillation), a framework enabling wearable-sensor models to be updated continuously without sacrificing performance on past tasks. CLAD-Net integrates a self-supervised transformer, acting as long-term memory, with a supervised Convolutional Neural Network (CNN) trained via knowledge distillation for activity classification. The transformer captures global activity patterns through cross-attention across body-mounted sensors, learning generalizable representations without labels. Meanwhile, the CNN leverages knowledge distillation to retain prior knowledge during subject-wise fine-tuning. On PAMAP2, CLAD-Net achieves 91.36% final accuracy with only 8.78% forgetting, surpassing memory-based and regularization-based baselines such as Experience Replay and Elastic Weight Consolidation. In semi-supervised settings with only 10-20% labeled data, CLAD-Net still delivers strong performance, demonstrating robustness to label scarcity. Ablation studies further validate each module's contribution.
@misc{azghan_cladnet25,
title={CLAD-Net: Continual Activity Recognition
in Multi-Sensor Wearable Systems},
author={Azghan, Reza Rahimi and Gudur, Gautham
Krishna and Malu, Mohit and Thomaz, Edison and
Pedrielli, Giulia and Turaga, Pavan and
Ghasemzadeh, Hassan},
year={2025},
eprint={2509.23077},
archivePrefix={arXiv}
}
|
 |
pdf /
abstract /
bibtex
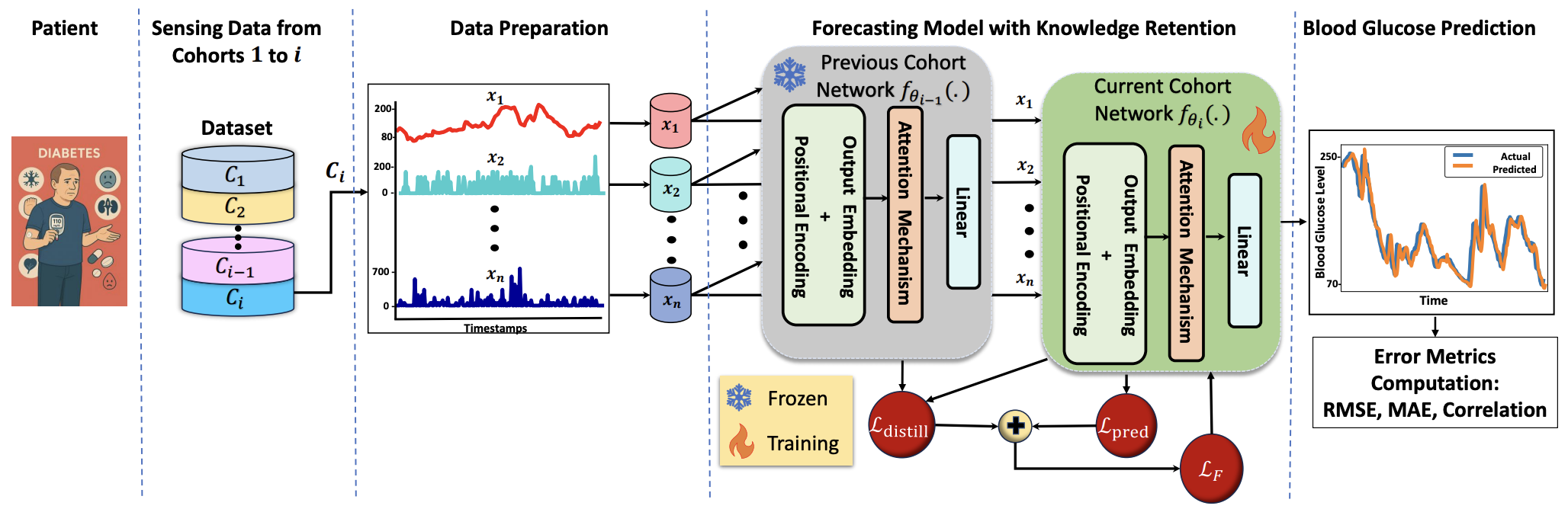
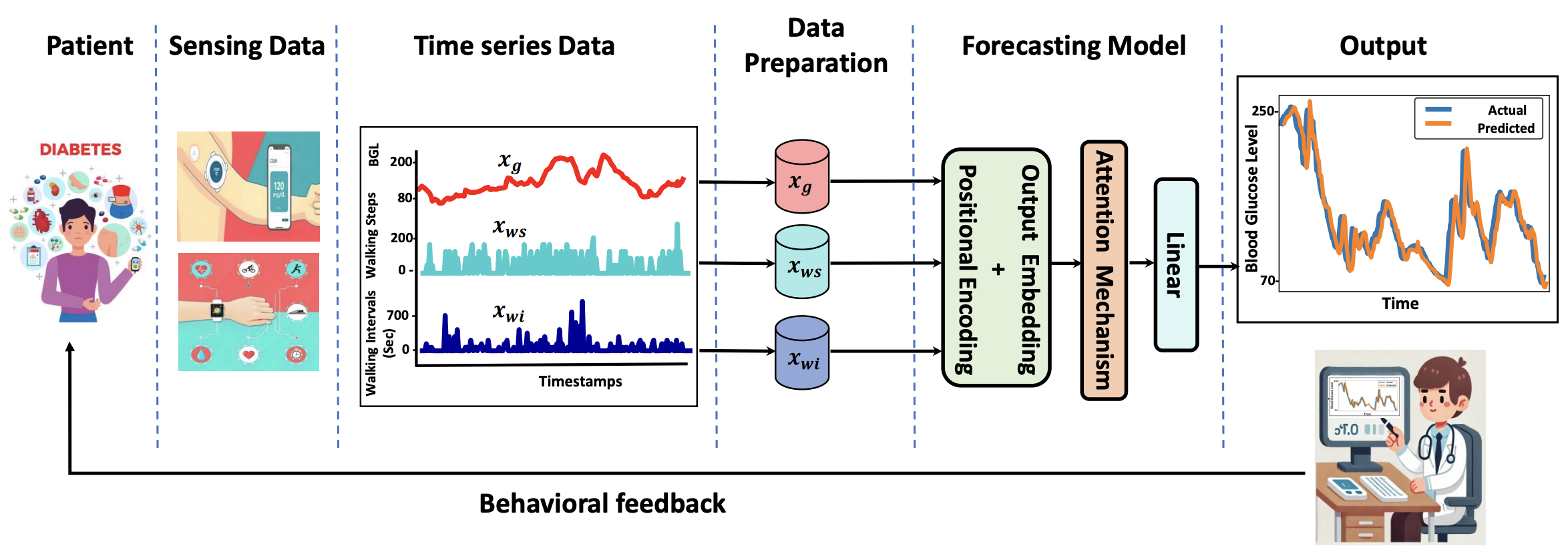
Diabetes is a chronic metabolic disorder characterized by persistently high blood glucose levels (BGLs), leading to severe complications such as cardiovascular disease, neuropathy, and retinopathy. Predicting BGLs enables patients to maintain glucose levels within a safe range and allows caregivers to take proactive measures through lifestyle modifications. Continuous Glucose Monitoring (CGM) systems provide real-time tracking, offering a valuable tool for monitoring BGLs. However, accurately forecasting BGLs remains challenging due to fluctuations due to physical activity, diet, and other factors. Recent deep learning models show promise in improving BGL prediction. Nonetheless, forecasting BGLs accurately from multimodal, irregularly sampled data over long prediction horizons remains a challenging research problem. In this paper, we propose AttenGluco, a multimodal Transformer-based framework for long-term blood glucose prediction. AttenGluco employs cross-attention to effectively integrate CGM and activity data, addressing challenges in fusing data with different sampling rates. Moreover, it employs multi-scale attention to capture long-term dependencies in temporal data, enhancing forecasting accuracy. To evaluate the performance of AttenGluco, we conduct forecasting experiments on the recently released AIREADI dataset, analyzing its predictive accuracy across different subject cohorts including healthy individuals, people with prediabetes, and those with type 2 diabetes. Furthermore, we investigate its performance improvements and forgetting behavior as new cohorts are introduced. Our evaluations show that AttenGluco improves all error metrics, such as root mean square error (RMSE), mean absolute error (MAE), and correlation, compared to the multimodal LSTM model. AttenGluco outperforms this baseline model by about 10% and 15% in terms of RMSE and MAE, respectively.This paper proposes GluMind, a transformer-based multimodal framework designed for continual and long-term blood glucose forecasting. GluMind devises two attention mechanisms, including cross-attention and multi-scale attention, which operate in parallel and deliver accurate predictive performance. Cross-attention effectively integrates blood glucose data with other physiological and behavioral signals such as activity, stress, and heart rate, addressing challenges associated with varying sampling rates and their adverse impacts on robust prediction. Moreover, the multi-scale attention mechanism captures long-range temporal dependencies. To mitigate catastrophic forgetting, GluMind incorporates a knowledge retention technique into the transformer-based forecasting model. The knowledge retention module not only enhances the model's ability to retain prior knowledge but also boosts its overall forecasting performance. We evaluate GluMind on the recently released AIREADI dataset, which contains behavioral and physiological data collected from healthy people, individuals with prediabetes, and those with type 2 diabetes. We examine the performance stability and adaptability of GluMind in learning continuously as new patient cohorts are introduced. Experimental results show that GluMind consistently outperforms other state-of-the-art forecasting models, achieving approximately 15% and 9% improvements in root mean squared error (RMSE) and mean absolute error (MAE), respectively.
@misc{farahmand_glumind25,
title={GluMind: Multimodal Parallel Attention
and Knowledge Retention for Robust
Cross-Population Blood Glucose Forecasting},
author={Farahmand, Ebrahim and Azghan,
Reza Rahimi and Chatrudi, Nooshin Taheri and
Ansu-Baidoo, Velarie Yaa and Kim, Eric and
Gudur, Gautham Krishna and Malu, Mohit and
Krueger, Owen and Thomaz, Edison and
Pedrielli, Giulia and Turaga, Pavan and
Ghasemzadeh, Hassan},
year={2025},
eprint={2509.18457},
archivePrefix={arXiv}
}
|
![[NEW]](images/new.png)
 |
pdf /
abstract /
code /
bibtex
Diabetes is a chronic metabolic disorder characterized by persistently high blood glucose levels (BGLs), leading to severe complications such as cardiovascular disease, neuropathy, and retinopathy. Predicting BGLs enables patients to maintain glucose levels within a safe range and allows caregivers to take proactive measures through lifestyle modifications. Continuous Glucose Monitoring (CGM) systems provide real-time tracking, offering a valuable tool for monitoring BGLs. However, accurately forecasting BGLs remains challenging due to fluctuations due to physical activity, diet, and other factors. Recent deep learning models show promise in improving BGL prediction. Nonetheless, forecasting BGLs accurately from multimodal, irregularly sampled data over long prediction horizons remains a challenging research problem. In this paper, we propose AttenGluco, a multimodal Transformer-based framework for long-term blood glucose prediction. AttenGluco employs cross-attention to effectively integrate CGM and activity data, addressing challenges in fusing data with different sampling rates. Moreover, it employs multi-scale attention to capture long-term dependencies in temporal data, enhancing forecasting accuracy. To evaluate the performance of AttenGluco, we conduct forecasting experiments on the recently released AIREADI dataset, analyzing its predictive accuracy across different subject cohorts including healthy individuals, people with prediabetes, and those with type 2 diabetes. Furthermore, we investigate its performance improvements and forgetting behavior as new cohorts are introduced. Our evaluations show that AttenGluco improves all error metrics, such as root mean square error (RMSE), mean absolute error (MAE), and correlation, compared to the multimodal LSTM model. AttenGluco outperforms this baseline model by about 10% and 15% in terms of RMSE and MAE, respectively.
@article{farahmand_attengluco25,
author = {Farahmand, Ebrahim and Azghan,
Reza Rahimi and Chatrudi, Nooshin Taheri,
and Kim, Eric and Gudur, Gautham Krishna
and Thomaz, Edison and Pedrielli, Giulia
and Turaga, Pavan and Ghasemzadeh, Hassan}
title = {AttenGluco: Multimodal
Transformer-Based Blood Glucose Forecasting
on AI-READI Dataset},
journal = {arXiv preprint arXiv:2502.09919},
year = {2025}
}
|
 |
pdf /
abstract /
poster /
code /
tweet /
bibtex
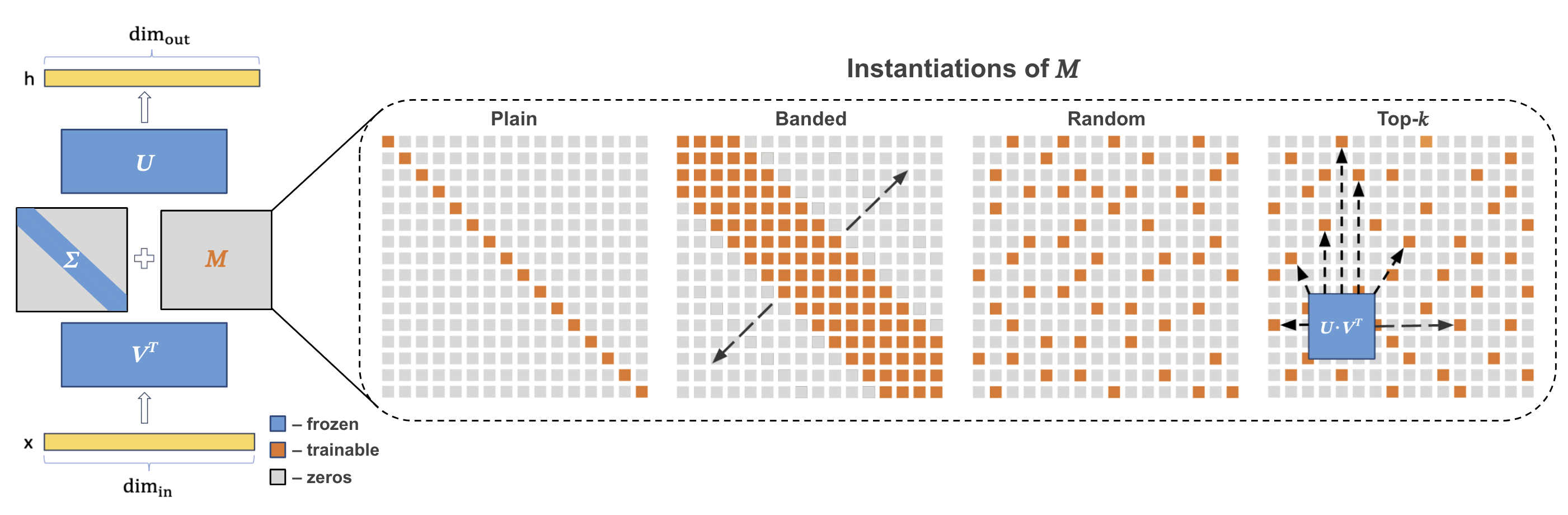
Popular parameter-efficient fine-tuning (PEFT) methods, such as LoRA and its variants, freeze pre-trained model weights W and inject learnable matrices ∆W. These ∆W matrices are structured for efficient parameterization, often using techniques like low-rank approximations or scaling vectors. However, these methods typically exhibit a performance gap compared to full fine-tuning. While recent PEFT methods have narrowed this gap, they do so at the expense of additional learnable parameters. We propose SVFT, a simple approach that structures ∆W based on the specific weight matrix W. SVFT updates W as a sparse combination M of outer products of its singular vectors, training only the coefficients of these combinations. Crucially, we make additional off-diagonal elements in M learnable, enabling a smooth trade-off between trainable parameters and expressivity — an aspect that distinctly sets our approach apart from previous works leveraging singular values. Extensive experiments on language and vision benchmarks show that SVFT recovers up to 96% of full fine-tuning performance while training only 0.006 to 0.25% of parameters, outperforming existing methods that achieve only up to 85% performance with 0.03 to 0.8% of the trainable parameter budget.
@inproceedings{lingam_neurips24,
title = {SVFT: Parameter-Efficient Fine-Tuning
with Singular Vectors},
author = {Lingam, Vijay and Tejaswi, Atula
and Vavre, Aditya and Shetty, Aneesh
and Gudur, Gautham Krishna and Ghosh, Joydeep
and Dimakis, Alex and Choi, Eunsol and
Bojchevski, Aleksandar and Sanghavi, Sujay},
pages = {41425--41446},
booktitle = {Advances in Neural Information
Processing Systems},
year = {2024}
}
|
 |
pdf /
abstract /
poster /
bibtex
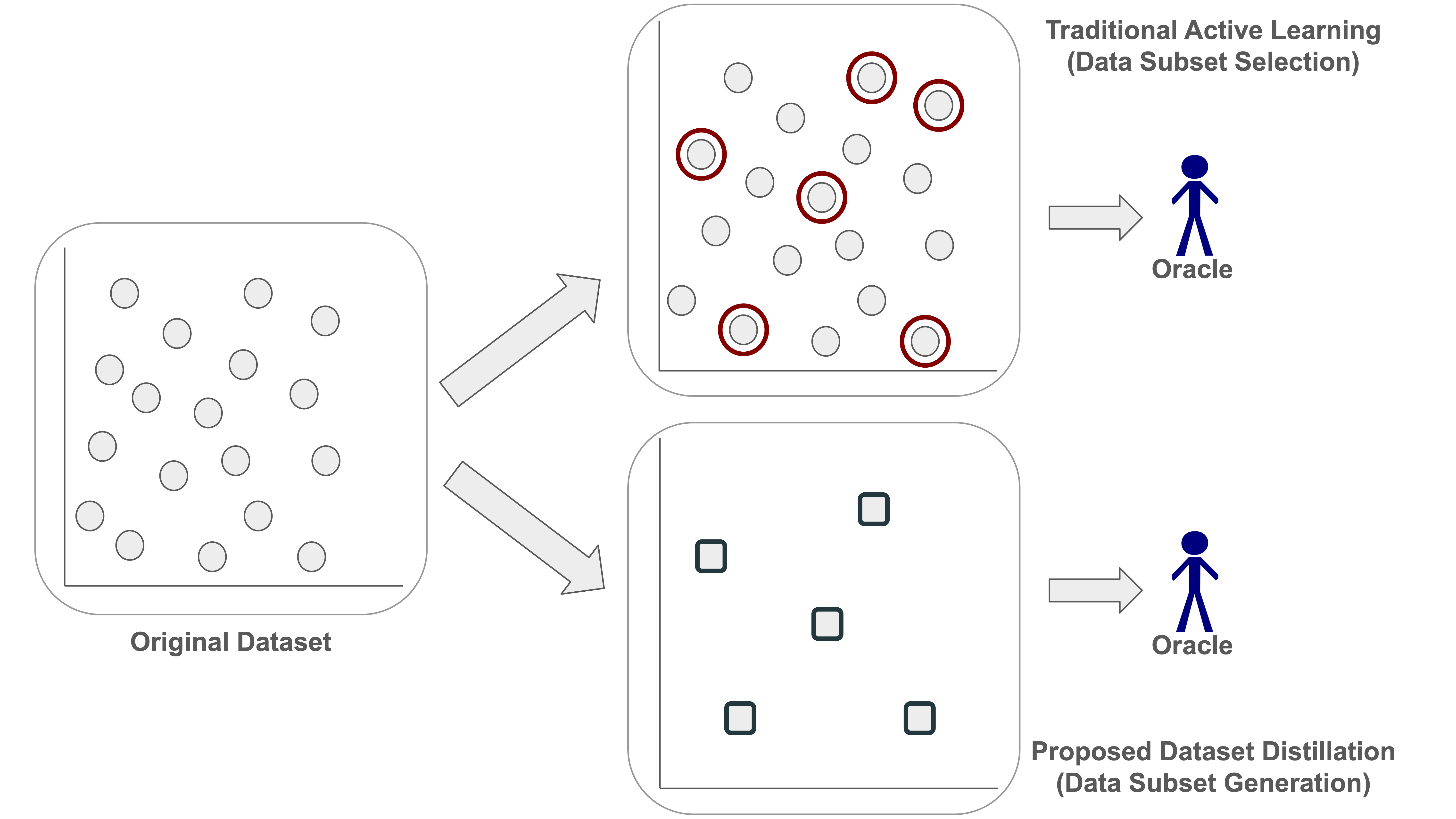
Audio classification tasks like keyword spotting and acoustic event detection often require large labeled datasets, which are computationally expensive and impractical for resource-constrained devices. While active learning techniques attempt to reduce labeling efforts by selecting the most informative samples, they struggle with scalability in real-world scenarios involving thousands of audio segments. In this paper, we introduce an approach that leverages dataset distillation as an alternative strategy to active learning to address the challenge of data efficiency in real-world audio classification tasks. Our approach synthesizes compact, high-fidelity coresets that encapsulate the most critical information from the original dataset, significantly reducing the labeling requirements while offering competitive performance. Through experiments on three benchmark datasets -- Google Speech Commands, UrbanSound8K, and ESC-50, our approach achieves up to a ~3,000x reduction in data points, and requires only a negligible fraction of the original training data while matching the performance of popular active learning baselines.
@inproceedings{gudur_enlsp24,
author = {Gudur, Gautham Krishna and
and Thomaz, Edison},
title = {Dataset Distillation for Audio
Classification: A Data-Efficient
Alternative to Active Learning},
booktitle = {NeurIPS 2024 Efficient
Natural Language and Speech Processing
(ENLSP-IV) Workshop},
year = {2024}
}
|
 |
pdf /
abstract /
poster /
code /
bibtex
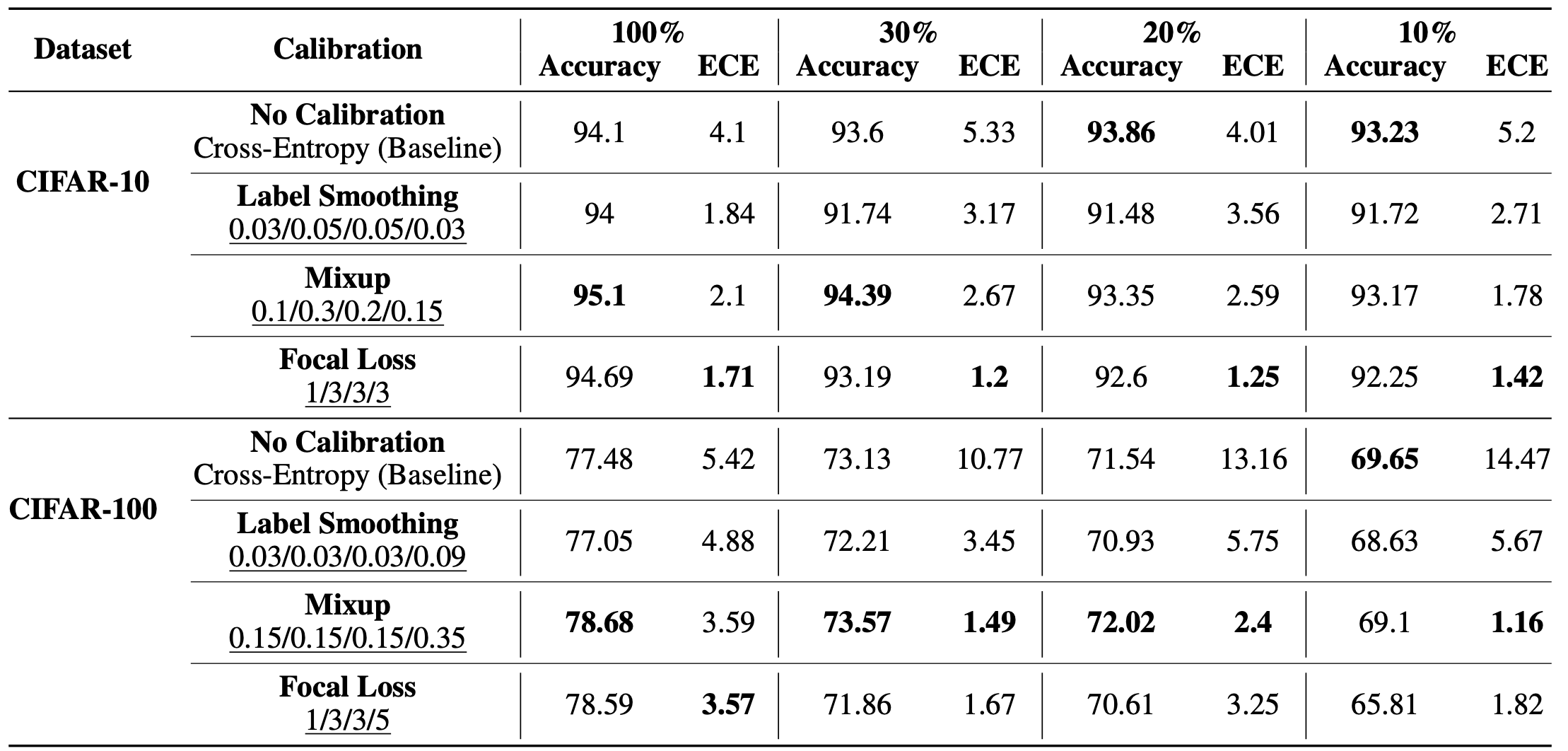
Calibration can reduce overconfident predictions of deep neural networks, but can calibration also accelerate training? In this paper, we show that it can when used to prioritize some examples for performing subset selection. We study the effect of popular calibration techniques in selecting better subsets of samples during training (also called sample prioritization) and observe that calibration can improve the quality of subsets, reduce the number of examples per epoch (by at least 70%), and can thereby speed up the overall training process. We further study the effect of using calibrated pre-trained models coupled with calibration during training to guide sample prioritization, which again seems to improve the quality of samples selected.
@inproceedings{tata_hity22,
author = {Tata, Ganesh and Gudur, Gautham Krishna
and Chennupati, Gopinath and
Khan, Mohammad Emtiyaz},
title = {Can Calibration Improve Sample
Prioritization?},
booktitle = {Has it Trained Yet?
NeurIPS 2022 Workshop},
year = {2022}
}
|
 |
pdf /
abstract /
slides /
bibtex
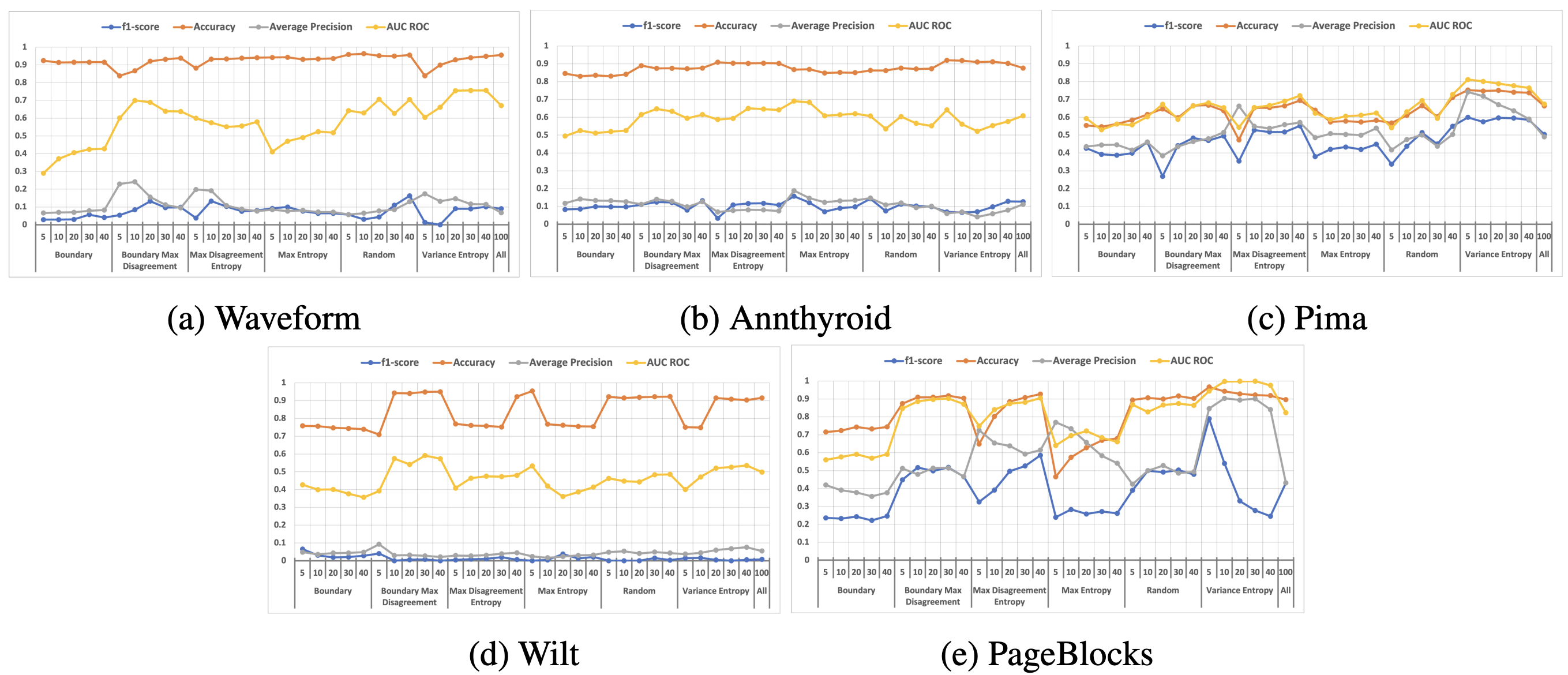
Anomaly Detection is a widely used technique in machine learning that identifies context-specific outliers. Most real-world anomaly detection applications are unsupervised, owing to the bottleneck of obtaining labeled data for a given context. In this paper, we solve two important problems pertaining to unsupervised anomaly detection. First, we identify only the most informative subsets of data points and obtain ground truths from the domain expert (oracle); second, we perform efficient model selection using a Bayesian Inference framework and recommend the top-k models to be fine-tuned prior to deployment. To this end, we exploit multiple existing and novel acquisition functions, and successfully demonstrate the effectiveness of the proposed framework using a weighted Ranking Score (\eta) to accurately rank the top-k models. Our empirical results show a significant reduction in data points acquired (with at least 60% reduction) while not compromising on the efficiency of the top-k models chosen, with both uniform and non-uniform priors over models.
@inproceedings{gudur_icmla22,
author = {Gudur, Gautham Krishna and Raaghul, R
and Adithya, K and Vasudevan, Shrihari},
title = {Data-Efficient Automatic Model
Selection in Unsupervised Anomaly Detection},
booktitle = {IEEE ICMLA 2022},
year = {2022}
}
|
 |
pdf /
abstract /
poster /
video /
slides /
bibtex
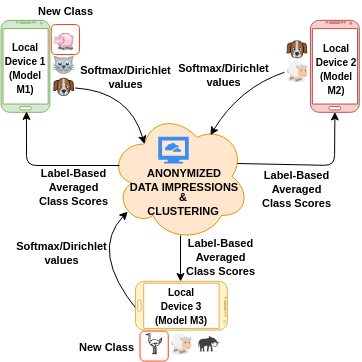
Federated learning is an effective way of extracting insights from different user devices while preserving the privacy of users. However, new classes with completely unseen data distributions can stream across any device in a federated learning setting, whose data cannot be accessed by the global server or other users. To this end, we propose a unified zero-shot framework to handle these aforementioned challenges during federated learning. We simulate two scenarios here – 1) when the new class labels are not reported by the user, the traditional FL setting is used; 2) when new class labels are reported by the user, we synthesize Anonymized Data Impressions by calculating class similarity matrices corresponding to each device’s new classes followed by unsupervised clustering to distinguish between new classes across different users. Moreover, our proposed framework can also handle statistical heterogeneities in both labels and models across the participating users. We empirically evaluate our framework on-device across different communication rounds (FL iterations) with new classes in both local and global updates, along with heterogeneous labels and models, on two widely used audio classification applications – keyword spotting and urban sound classification, and observe an average deterministic accuracy increase of ∼4.041% and ∼4.258% respectively.
@inproceedings{gudur_interspeech21,
author = {Gudur, Gautham Krishna and
Perepu, Satheesh Kumar},
title = {Zero-Shot Federated Learning with
New Classes for Audio Classification},
booktitle = {Proc. Interspeech 2021},
pages = {1579--1583},
year = {2021},
doi = {10.21437/Interspeech.2021-2264}
}
|
 |
pdf /
abstract /
poster /
bibtex
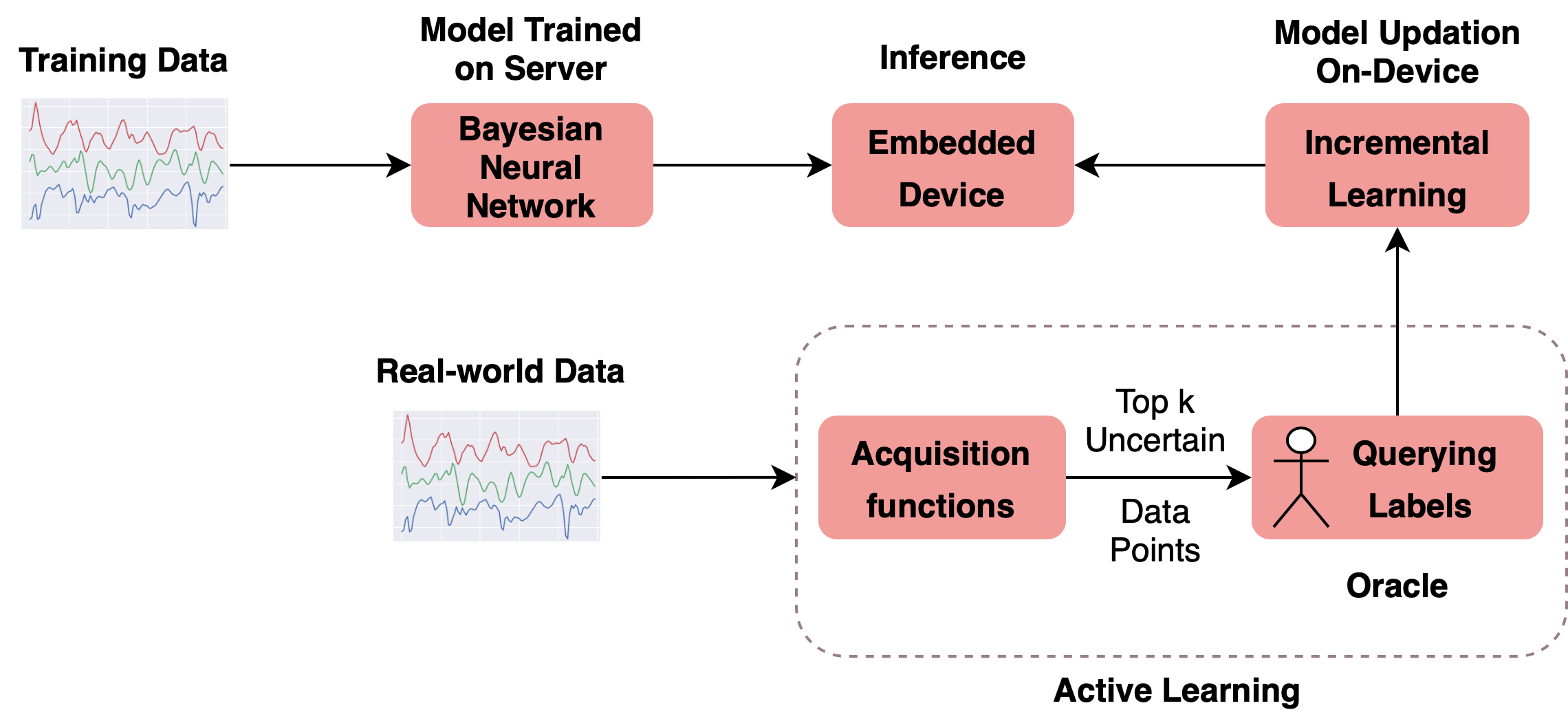
In the recent past, psychological stress has been increasingly observed in humans, and early detection is crucial to prevent health risks. Stress detection using ondevice deep learning algorithms has been on the rise owing to advancements in pervasive computing. However, an important challenge that needs to be addressed is handling unlabeled data in real-time via suitable ground truthing techniques (like Active Learning), which should help establish affective states (labels) while also selecting only the most informative data points to query from an oracle. In this paper, we propose a framework with capabilities to represent model uncertainties through approximations in Bayesian Neural Networks using Monte-Carlo (MC) Dropout. This is combined with suitable acquisition functions for active learning. Empirical results on a popular stress and affect detection dataset experimented on a Raspberry Pi 2 indicate that our proposed framework achieves a considerable efficiency boost during inference, with a substantially low number of acquired pool points during active learning across various acquisition functions. Variation Ratios achieves an accuracy of 90.38% which is comparable to the maximum test accuracy achieved while training on about 40% lesser data.
@article{ragav_mlmh20,
author = {Ragav, Abhijith and
Gudur, Gautham Krishna},
title = {Bayesian Active Learning for
Wearable Stress and Affect Detection},
journal = {arXiv preprint arXiv:2012.02702},
year = {2020}
}
|
 |
pdf /
abstract /
poster /
slides /
bibtex
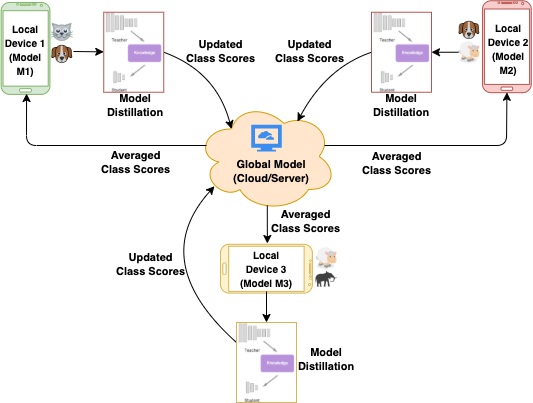
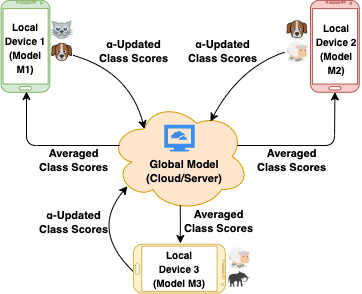
One of the most significant applications in pervasive computing for modeling user behavior is Human Activity Recognition (HAR). Such applications necessitate us to characterize insights from multiple resource-constrained user devices using machine learning techniques for effective personalized activity monitoring. On-device Federated Learning proves to be an extremely viable option for distributed and collaborative machine learning in such scenarios, and is an active area of research. However, there are a variety of challenges in addressing statistical (non-IID data) and model heterogeneities across users. In addition, in this paper, we explore a new challenge of interest - to handle heterogeneities in labels (activities) across users during federated learning. To this end, we propose a framework with two different versions for federated label-based aggregation, which leverage overlapping information gain across activities - one using Model Distillation Update, and the other using Weighted \alpha$-update. Empirical evaluation on the Heterogeneity Human Activity Recognition (HHAR) dataset (with four activities for effective elucidation of results) indicates an average deterministic accuracy increase of at least ~11.01% with the model distillation update strategy and ~9.16% with the weighted \alpha-update strategy. We demonstrate the on-device capabilities of our proposed framework by using Raspberry Pi 2, a single-board computing platform.
@inproceedings{gudur_dlhar20,
author = {Gudur, Gautham Krishna and
Perepu, Satheesh K},
title = {Resource-Constrained Federated Learning
with Heterogeneous Labels and Models for
Human Activity Recognition},
booktitle = {Deep Learning for Human Activity
Recognition},
pages = {55--69},
year = {2021},
publisher={Springer Singapore}
}
@article{gudur_mlmh20,
author = {Gudur, Gautham Krishna and
Perepu, Satheesh K},
title = {Federated Learning with Heterogeneous
Labels and Models for Mobile Activity
Monitoring},
journal = {arXiv preprint arXiv:2012.02539},
year = {2020}
}
|
 |
pdf /
abstract /
slides /
bibtex
Various IoT applications demand resource-constrained machine learning mechanisms for different applications such as pervasive healthcare, activity monitoring, speech recognition, real-time computer vision, etc. This necessitates us to leverage information from multiple devices with few communication overheads. Federated Learning proves to be an extremely viable option for distributed and collaborative machine learning. Particularly, on-device federated learning is an active area of research, however, there are a variety of challenges in addressing statistical (non-IID data) and model heterogeneities. In addition, in this paper we explore a new challenge of interest - to handle label heterogeneities in federated learning. To this end, we propose a framework with simple $\alpha$-weighted federated aggregation of scores which leverages overlapping information gain across labels, while saving bandwidth costs in the process. Empirical evaluation on Animals-10 dataset (with 4 labels for effective elucidation of results) indicates an average deterministic accuracy increase of at least ~16.7%. We also demonstrate the on-device capabilities of our proposed framework by experimenting with federated learning and inference across different iterations on a Raspberry Pi 2, a single-board computing platform.
@article{gudur_aiot20,
author = {Gudur, Gautham Krishna and Balaji,
Bala Shyamala and Perepu, Satheesh K},
title = {Resource-Constrained Federated Learning
with Heterogeneous Labels and Models},
journal = {arXiv preprint arXiv:2011.03206},
year = {2020}
}
|
 |
pdf /
abstract /
bibtex
Demand Forecasting is a primary revenue management strategy in any business model, particularly in the highly volatile entertainment/movie industry wherein, inaccurate forecasting may lead to loss in revenue, improper workforce allocation and food wastage or shortage. Predominant challenges in Occupancy Forecasting might involve complexities in modeling external factors – particularly in Indian multiplexes with multilingual movies, high degrees of uncertainty in crowdbehavior, seasonality drifts, influence of socio-economic events and weather conditions. In this paper, we investigate the problem of movie occupancy forecasting, a significant step in the decision making process of movie scheduling and resource management, by leveraging the historical transactions performed in a multiplex consisting of eight screens with an average footfall of over 5500 on holidays and over 3500 on nonholidays every day. To effectively capture crowd behavior and predict the occupancy, we engineer and benchmark behavioral features by structuring recent historical transaction data spanning over five years from one of the top Indian movie multiplex chains, and propose various deep learning and conventional machine learning models. We also propose and optimize on a novel feature called Sale Velocity to incorporate the dynamic crowd behavior in movies. The performance of these models are benchmarked in real-time using Mean Absolute Percentage Error (MAPE), and found to be highly promising while substantially outperforming a domain expert’s predictions.
@inproceedings{venkataramani_icdmw19,
author = {Venkataramani, Sundararaman and
Ramesh, Ateendra and S, Sharan Sundar and
Jain, Aashish Kumar and Gudur, Gautham Krishna
and Vijayaraghavan, Vineeth},
title = {A Dynamically Adaptive Movie Occupancy
Forecasting System with Feature Optimization},
booktitle = {International Conference on Data
Mining Workshops (ICDMW)},
pages = {799--805},
year = {2019},
organization = {IEEE}
}
|
 |
pdf /
abstract /
code /
slides /
bibtex
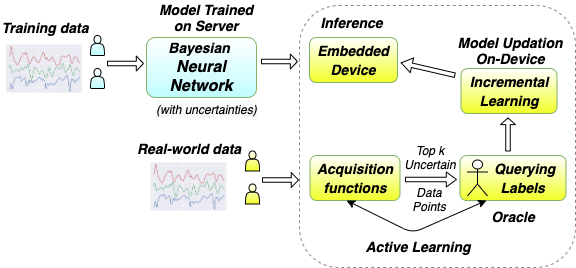
Intelligent public transportation systems are the cornerstone to any smart city, given the advancements made in the field of self-driving autonomous vehicles - particularly for autonomous buses, where it becomes really difficult to systematize a way to identify the arrival of a bus stop on-the-fly for the bus to appropriately halt and notify its passengers. This paper proposes an automatic and intelligent bus stop recognition system built on computer vision techniques, deployed on a low-cost single-board computing platform with minimal human supervision. The on-device recognition engine aims to extract the features of a bus stop and its surrounding environment, which eliminates the need for a conventional Global Positioning System (GPS) look-up, thereby alleviating network latency and accuracy issues. The dataset proposed in this paper consists of images of 11 different bus stops taken at different locations in Chennai, India during day and night. The core engine consists of a convolutional neural network (CNN) of size ~260 kB that is computationally lightweight for training and inference. In order to automatically scale and adapt to the dynamic landscape of bus stops over time, incremental learning (model updation) techniques were explored on-device from real-time incoming data points. Real-time incoming streams of images are unlabeled, hence suitable ground truthing strategies (like Active Learning), should help establish labels on-the-fly. Light-weight Bayesian Active Learning strategies using Bayesian Neural Networks using dropout (capable of representing model uncertainties) enable selection of the most informative images to query from an oracle. Intelligent rendering of the inference module by iteratively looking for better images on either sides of the bus stop environment propels the system towards human-like behavior. The proposed work can be integrated seamlessly into the widespread existing vision-based self-driving autonomous vehicles.
@inproceedings{gudur_purba19,
author = {Gudur, Gautham Krishna and Ramesh,
Ateendra and R, Srinivasan},
title = {A Vision-Based Deep On-Device
Intelligent Bus Stop Recognition System},
booktitle = {Adjunct Proceedings of the 2019 ACM
International Joint Conference on Pervasive and
Ubiquitous Computing and Proceedings of the 2019
ACM International Symposium on Wearable Computers},
pages = {963--968},
numpages = {6},
year = {2019}
}
|
 |
pdf /
abstract /
poster /
code /
bibtex
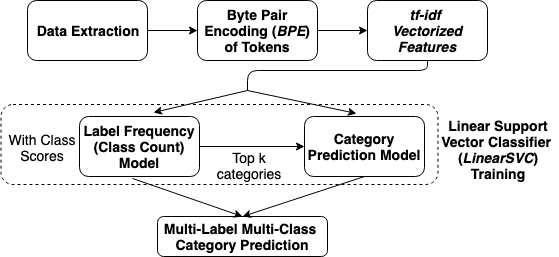
In this paper, we (Team Raghavan) describe the system of our submission for GermEval 2019 Task 1 - Subtask (a) and Subtask (b), which are multi-label multi-class classification tasks. The goal is to classify short texts describing German books into one or multiple classes, 8 generic categories for Subtask (a) and 343 specific categories for Subtask (b). Our system comprises of three stages. (a) Transform multi-label multi-class problem into single-label multi-class problem. Build a category model. (b) Build a class count model to predict the number of classes a given input belongs to. (c) Transform single-label problem into multi-label problem back again by selecting the top-k predictions from the category model, with the optimal k value predicted from the class count model. Our approach utilizes a Support Vector Classification model on the extracted vectorized tf-idf features by leveraging the Byte-Pair Token Encoding (BPE), and reaches f1-micro scores of 0.857 in the test evaluation phase and 0.878 in post evaluation phase for Subtask (a), while 0.395 in post evaluation phase for Subtask (b) of the competition. We have provided our solution code in the following link: https://github.com/oneraghavan/germeval-2019.
@inproceedings{raghavan_konvens19,
author = {Raghavan, AK and Umaashankar, Venkatesh
and Gudur, Gautham Krishna},
title = {Label Frequency Transformation for
Multi-Label Multi-Class Text Classification},
booktitle = {Proceedings of the 15th Conference on
Natural Language Processing (KONVENS 2019)},
pages = {341--346},
year = {2019},
}
|
 |
pdf /
abstract /
code /
video /
slides /
bibtex
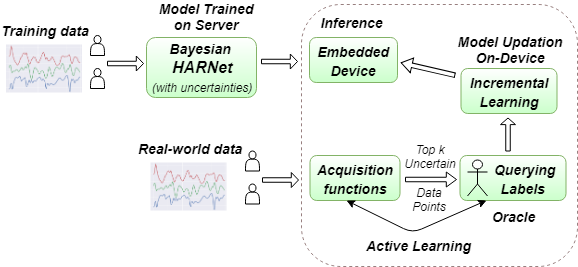
Various health-care applications such as assisted living, fall detection etc., require modeling of user behavior through Human Activity Recognition (HAR). HAR using mobile- and wearable-based deep learning algorithms have been on the rise owing to the advancements in pervasive computing. However, there are two other challenges that need to be addressed: first, the deep learning model should support on-device incremental training (model updation) from real-time incoming data points to learn user behavior over time, while also being resource-friendly; second, a suitable ground truthing technique (like Active Learning) should help establish labels on-the-fly while also selecting only the most informative data points to query from an oracle. Hence, in this paper, we propose ActiveHARNet, a resource-efficient deep ensembled model which supports on-device Incremental Learning and inference, with capabilities to represent model uncertainties through approximations in Bayesian Neural Networks using dropout. This is combined with suitable acquisition functions for active learning. Empirical results on two publicly available wrist-worn HAR and fall detection datasets indicate that ActiveHARNet achieves considerable efficiency boost during inference across different users, with a substantially low number of acquired pool points (at least 60% reduction) during incremental learning on both datasets experimented with various acquisition functions, thus demonstrating deployment and Incremental Learning feasibility.
@inproceedings{gudur_emdl19,
author = {Gudur, Gautham Krishna and
Sundaramoorthy, Prahalathan and
Umaashankar, Venkatesh},
title = {ActiveHARNet: Towards On-Device
Deep Bayesian Active Learning for Human
Activity Recognition},
booktitle = {The 3rd International Workshop
on Deep Learning for Mobile Systems and
Applications},
pages = {7--12},
numpages = {6},
year = {2019}
}
|
 |
pdf /
abstract /
code /
slides /
bibtex
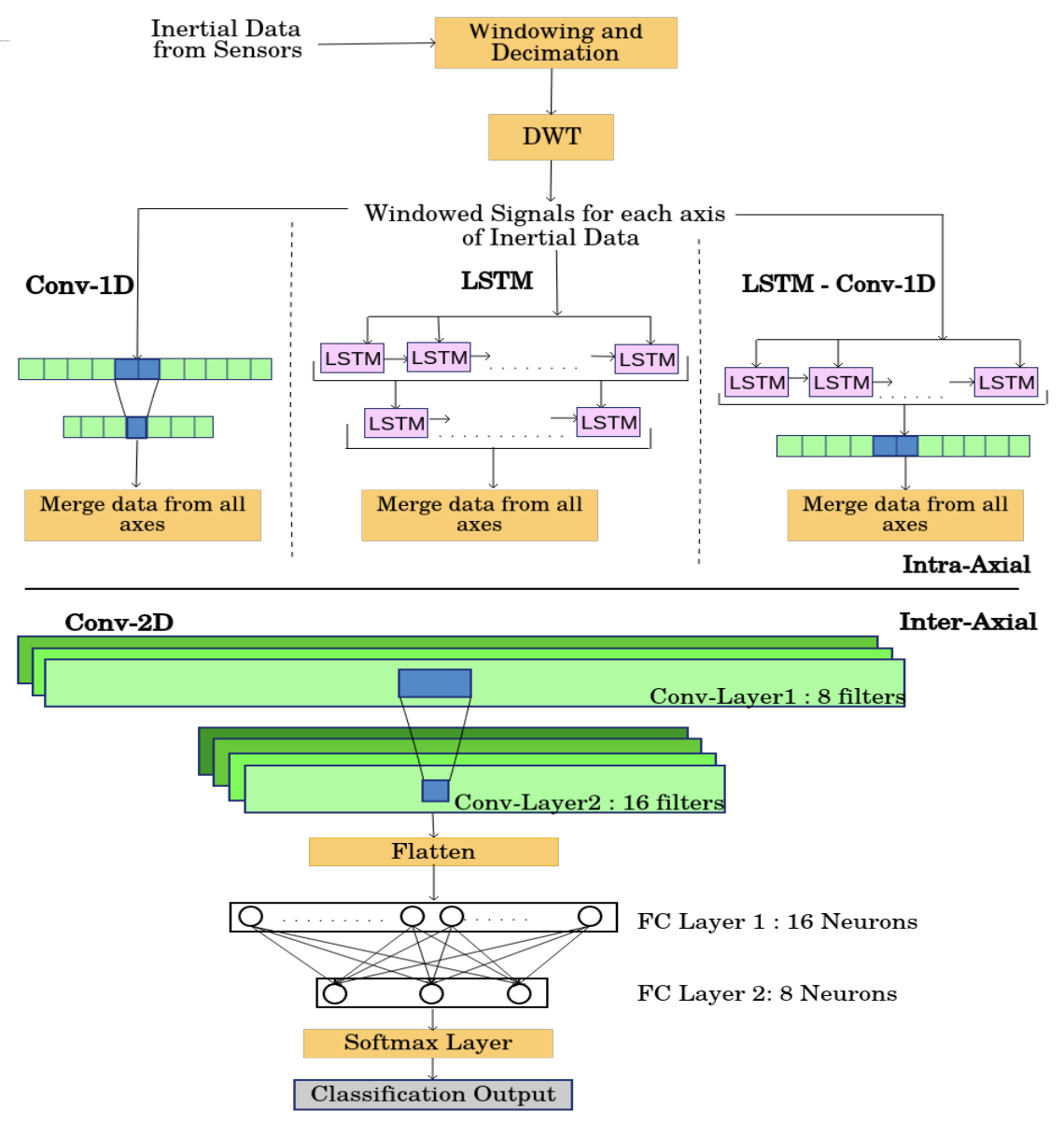
Recent advancements in the domain of pervasive computing have seen the incorporation of sensor-based Deep Learning algorithms in Human Activity Recognition (HAR). Contemporary Deep Learning models are engineered to alleviate the difficulties posed by conventional Machine Learning algorithms which require extensive domain knowledge to obtain heuristic hand-crafted features. Upon training and deployment of these Deep Learning models on ubiquitous mobile/embedded devices, it must be ensured that the model adheres to their computation and memory limitations, in addition to addressing the various mobile- and user-based heterogeneities prevalent in actuality. To handle this, we propose HARNet - a resource-efficient and computationally viable network to enable on-line Incremental Learning and User Adaptability as a mitigation technique for anomalous user behavior in HAR. Heterogeneity Activity Recognition Dataset was used to evaluate HARNet and other proposed variants by utilizing acceleration data acquired from diverse mobile platforms across three different modes from a practical application perspective. We perform Decimation as a Down-sampling technique for generalizing sampling frequencies across mobile devices, and Discrete Wavelet Transform for preserving information across frequency and time. Systematic evaluation of HARNet on User Adaptability yields an increase in accuracy by ~35% by leveraging the model's capability to extract discriminative features across activities in heterogeneous environments.
@inproceedings{sundaramoorthy_emdl18,
author = {Sundaramoorthy, Prahalathan and
Gudur, Gautham Krishna and Moorthy,
Manav Rajiv and Bhandari, R Nidhi and
Vijayaraghavan, Vineeth},
title = {HARNet: Towards On-Device
Incremental Learning Using Deep Ensembles
on Constrained Devices},
booktitle = {Proceedings of the 2nd International
Workshop on Embedded and Mobile Deep Learning},
pages = {31--36},
numpages = {6}
year = {2018}
}
|
 |
pdf /
abstract /
code /
slides /
bibtex
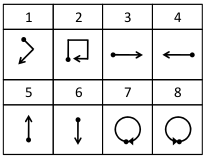
Human computer interaction facilitates intelligent communication between humans and computers, in which gesture recognition plays a prominent role. This paper proposes a machine learning system to identify dynamic gestures using triaxial acceleration data acquired from two public datasets. These datasets, uWave and Sony, were acquired using accelerometers embedded in Wii remotes and smartwatches, respectively. A dynamic gesture signed by the user is characterized by a generic set of features extracted across time and frequency domains. The system was analyzed from an end-user perspective and was modelled to operate in three modes. The modes of operation determine the subsets of data to be used for training and testing the system. From an initial set of seven classifiers, three were chosen to evaluate each dataset across all modes rendering the system towards mode-neutrality and dataset-independence. The proposed system is able to classify gestures performed at varying speeds with minimum preprocessing, making it computationally efficient. Moreover, this system was found to run on a low-cost embedded platform – Raspberry Pi Zero (USD 5), making it economically viable.
@inproceedings{krishna_ficc18,
author = {Krishna, G Gautham and Nathan,
Karthik Subramanian and Kumar, B Yogesh
and Prabhu, Ankith A and Kannan, Ajay and
Vijayaraghavan, Vineeth},
title = {A Generic Multi-modal Dynamic Gesture
Recognition System Using Machine Learning},
booktitle = {Future of Information and
Communication Conference},
pages = {603--615},
year = {2018},
organization = {Springer}
}
|
 |
pdf /
abstract /
slides /
bibtex
The film industry has been a major factor in the rapid growth of the Indian entertainment industry. While watching a film, the viewers undergo an experience that evolves over time, thereby grabbing their attention. This triggers a sequence of processes which is perceptual, cognitive and emotional. Neurocinematics is an emerging field of research, that measures the cognitive responses of a film viewer. Neurocinematic studies, till date, have been performed using functional magnetic resonance imaging (fMRI); however recent studies have suggested the use of advancements in electroencephalography (EEG) in neurocinematics to address the issues involved with fMRI. In this article the emotions corresponding to two different genres of Indian films are captured with the real-time brainwaves of viewers using EEG and analyzed using R language.
@inproceedings{krishna_icaicr17,
author={G, Gautham Krishna and Krishna, G and
Bhalaji, N},
title = {Electroencephalography Based Analysis
of Emotions Among Indian Film Viewers},
booktitle = {International Conference on Advanced
Informatics for Computing Research},
pages = {145--155},
year = {2017},
organization = {Springer}
}
|
 |
pdf /
abstract /
bibtex
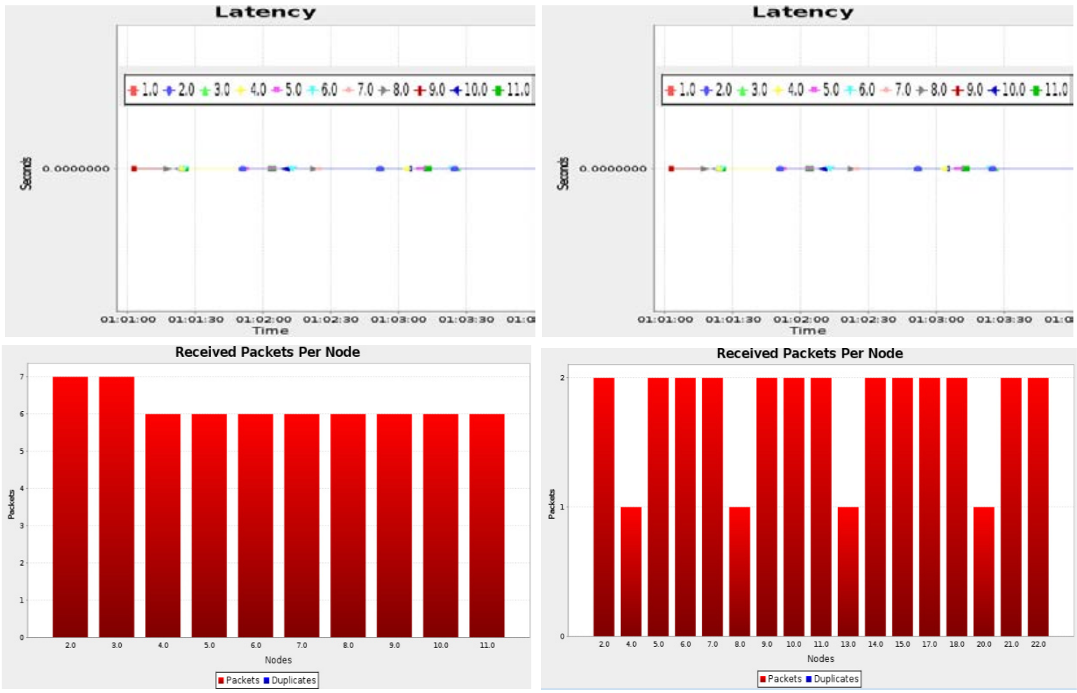
The wide-scaled sensing by Wireless Sensor Networks (WSN) has impacted several areas in the modern generation. It has offered the ability to measure, observe and understand the various physical factors from our environment. The rapid increase of WSN devices in an actuating-communicating network has led to the evolution of Internet of Things (IoT), where information is shared seamlessly across platforms by blending the sensors and actuators with our environment. These low cost WSN devices provide automation in medical and environmental monitoring. Evaluating the performance of these sensors using RPL enhances their use in real world applications. The realization of these RPL performances from different nodes focuses our study to utilize WSNs in our day-to-day applications. The effective sensor nodes (motes) for the appropriate environmental scenarios are analyzed, and we propose a collective view of the metrics for the same, for enhanced throughput in the given field of usage.
@article{krishna_icrtcse16,
author = {Krishna, G Gautham and Krishna, G
and Bhalaji, N},
title = {Analysis of Routing Protocol for Low-power
and Lossy Networks in IoT Real Time Applications},
journal = {Procedia Computer Science},
volume = {87},
pages = {270--274},
year = {2016},
publisher={Elsevier}
}
|
|
|
 |
|
|
|
 |
|
 |
|
|
|
|
|
|